
BACK TO BLOG
Техники обхода LinkedList
Обход связного списка является фундаментальной техникой работы с этой структурой данных. В отличие от массива, здесь нет случайного доступа по индексу, поэтому движение происходит шаг за шагом по ссылкам. У обхода есть разные варианты. Каждый из них решает свои задачи и имеет нюансы: где-то легко забыть обновить указатель, где-то важно учесть границы.
Освоение всех типов обхода даёт уверенность и готовит к более сложным приёмам: реверсу, удалению, работе с двумя указателями.
Виды обхода
Классический обход
Идея: Последовательно пройти от head до null, обработать каждый узел.
Где применяют: Печать значений, подсчёт длины, поиск первого совпадения, подготовка к более сложным техникам.
Как работает (pseudocode):
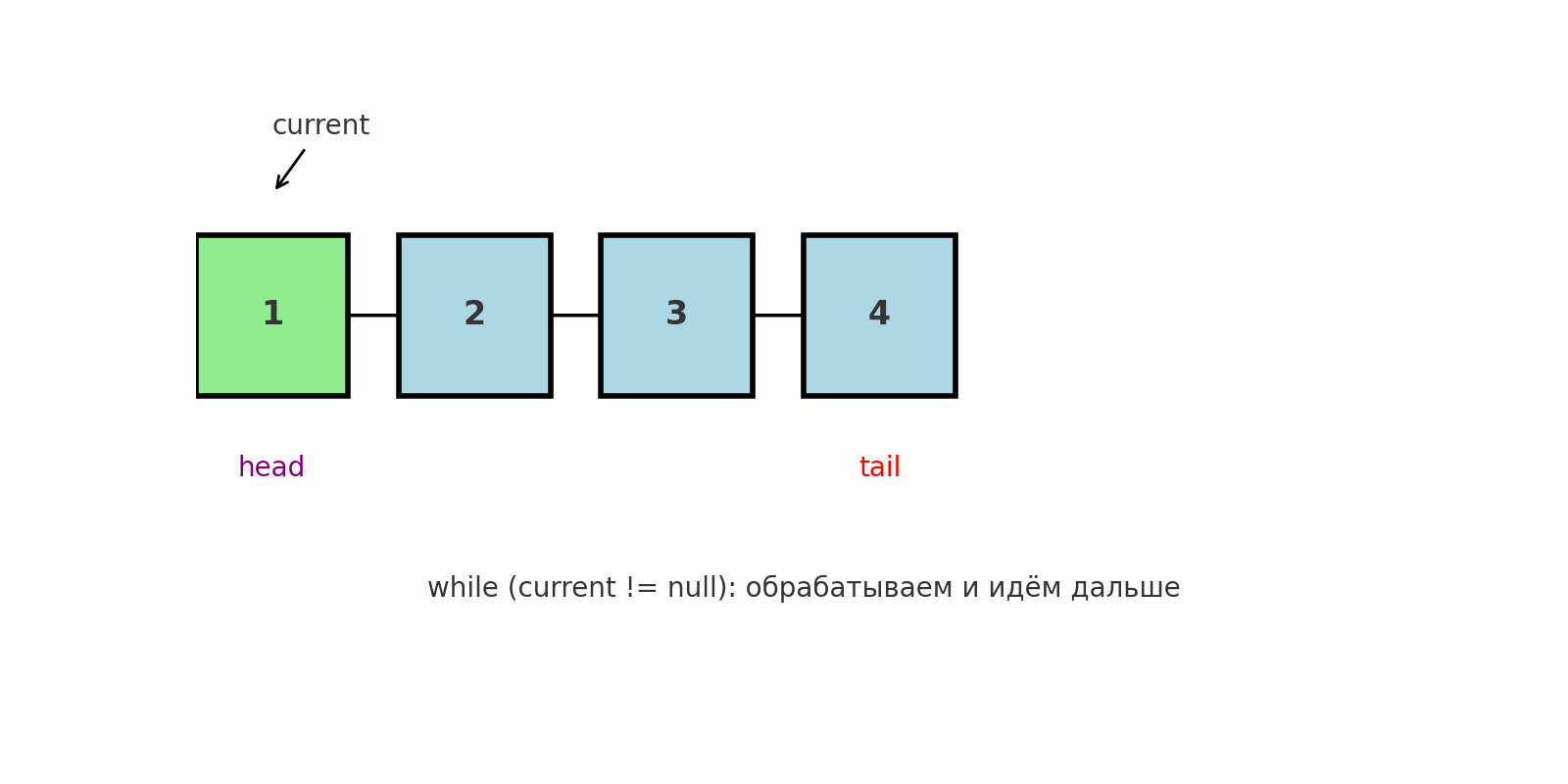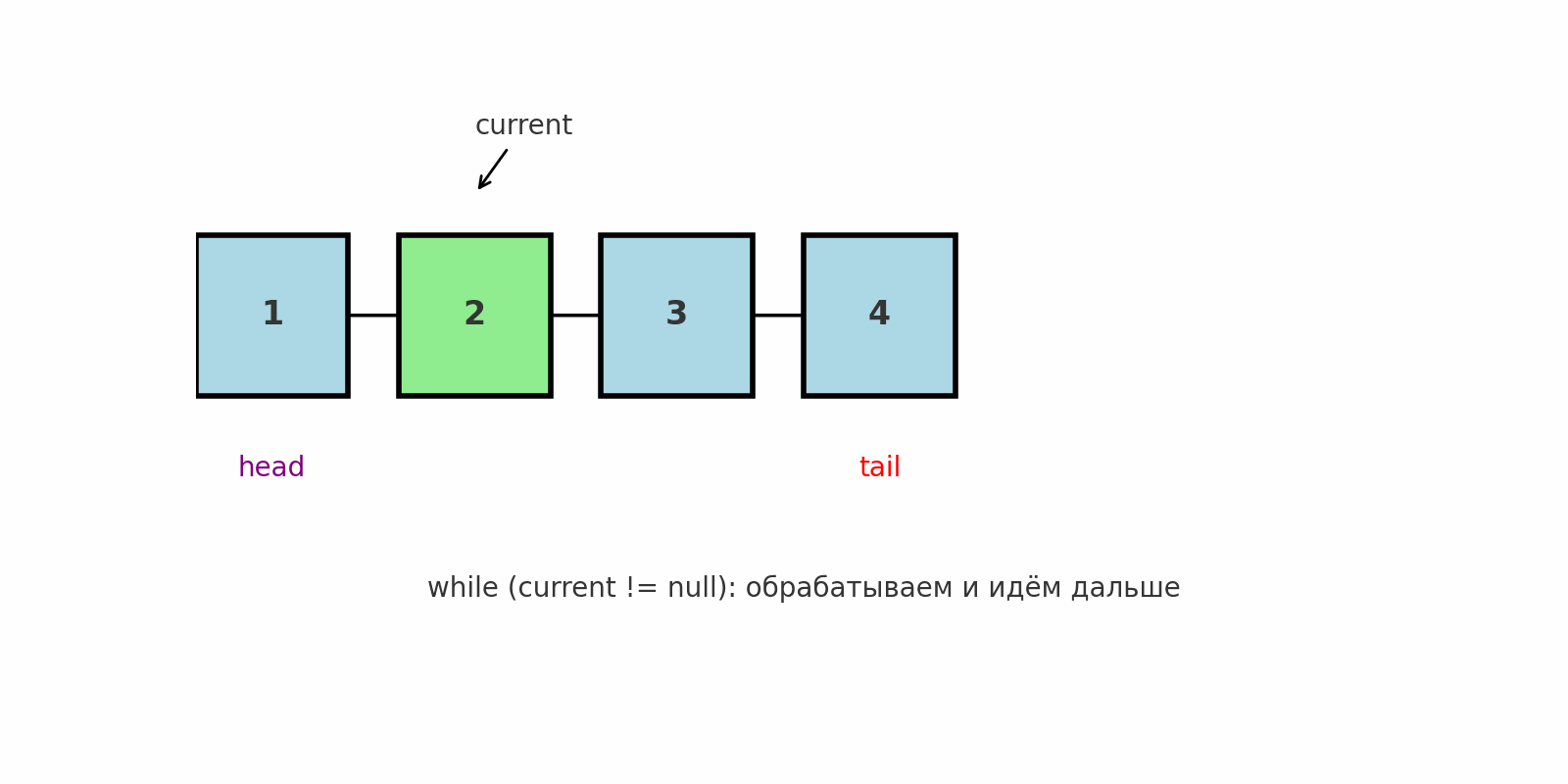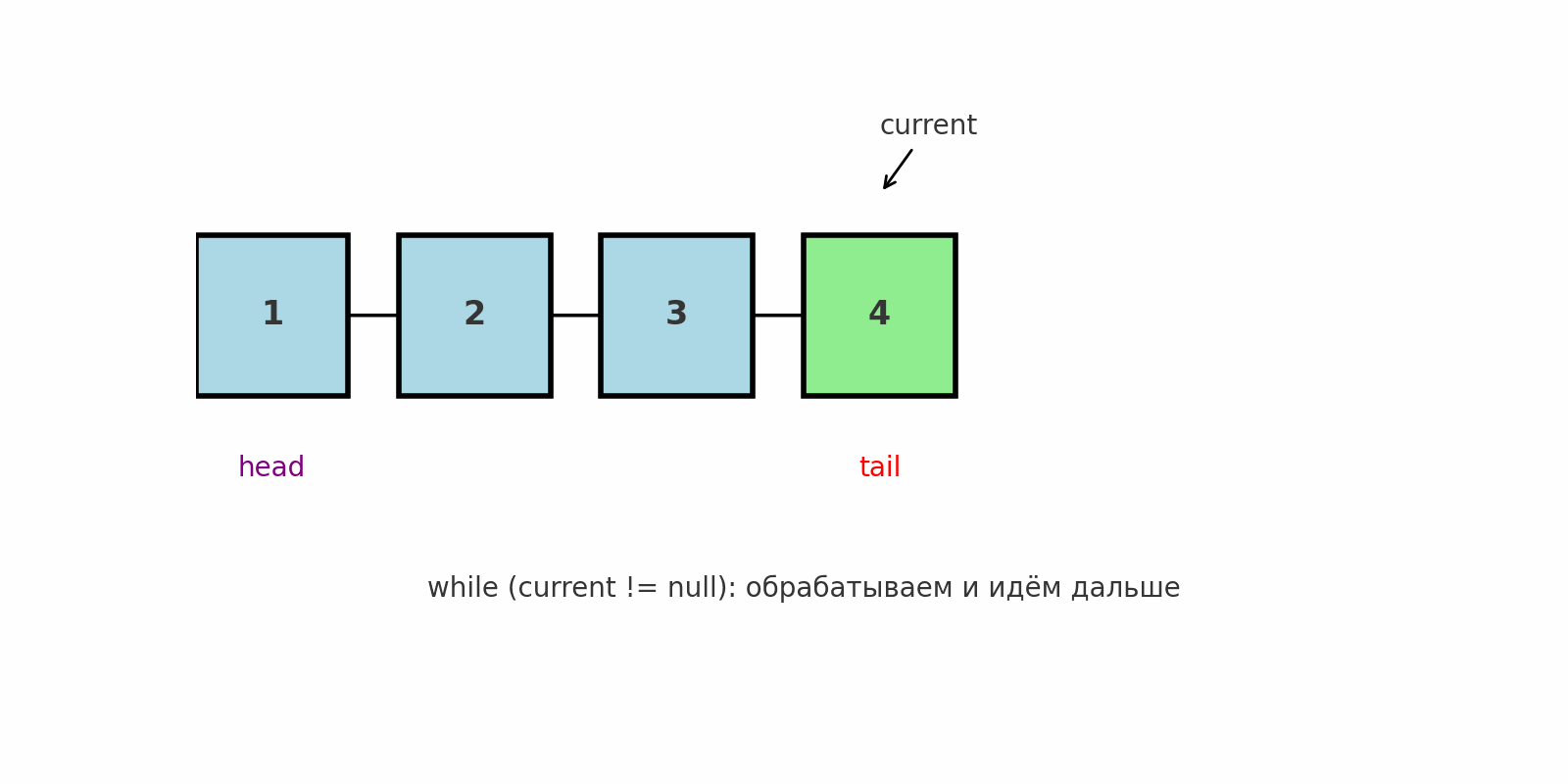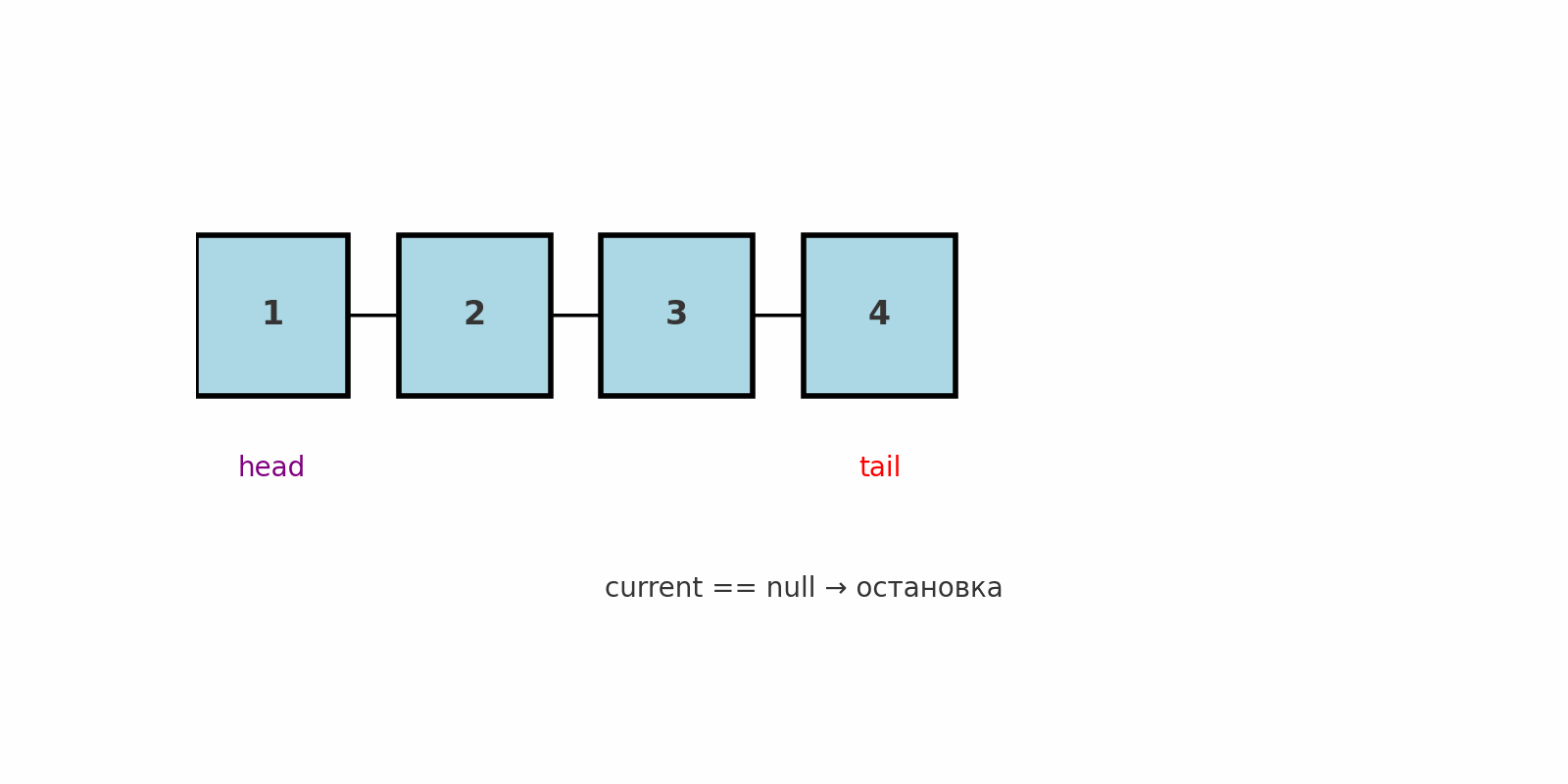
Подводные камни:
Обработка пустого списка: цикл не должен начинаться, если
head == null.При долгих проверках лучше предусматривать ранний выход, чтобы не проходить список до конца без нужды.
Ошибки:
Забытое обновление
current = current.nextведёт к бесконечному циклу.Мутирование ссылок
current.nextвнутри цикла без сохранения временной переменной может порвать цепочку.
Обход с
prev + current
Идея: одновременно хранить ссылки на предыдущий (prev) и текущий (current) узлы. Это нужно, потому что в односвязном списке нет ссылки назад, и без prev невозможно безопасно менять связи.
Где применяют: удаление или вставка в середину списка, задачи, где нужно знать «соседа слева».
Как работает (pseudocode):
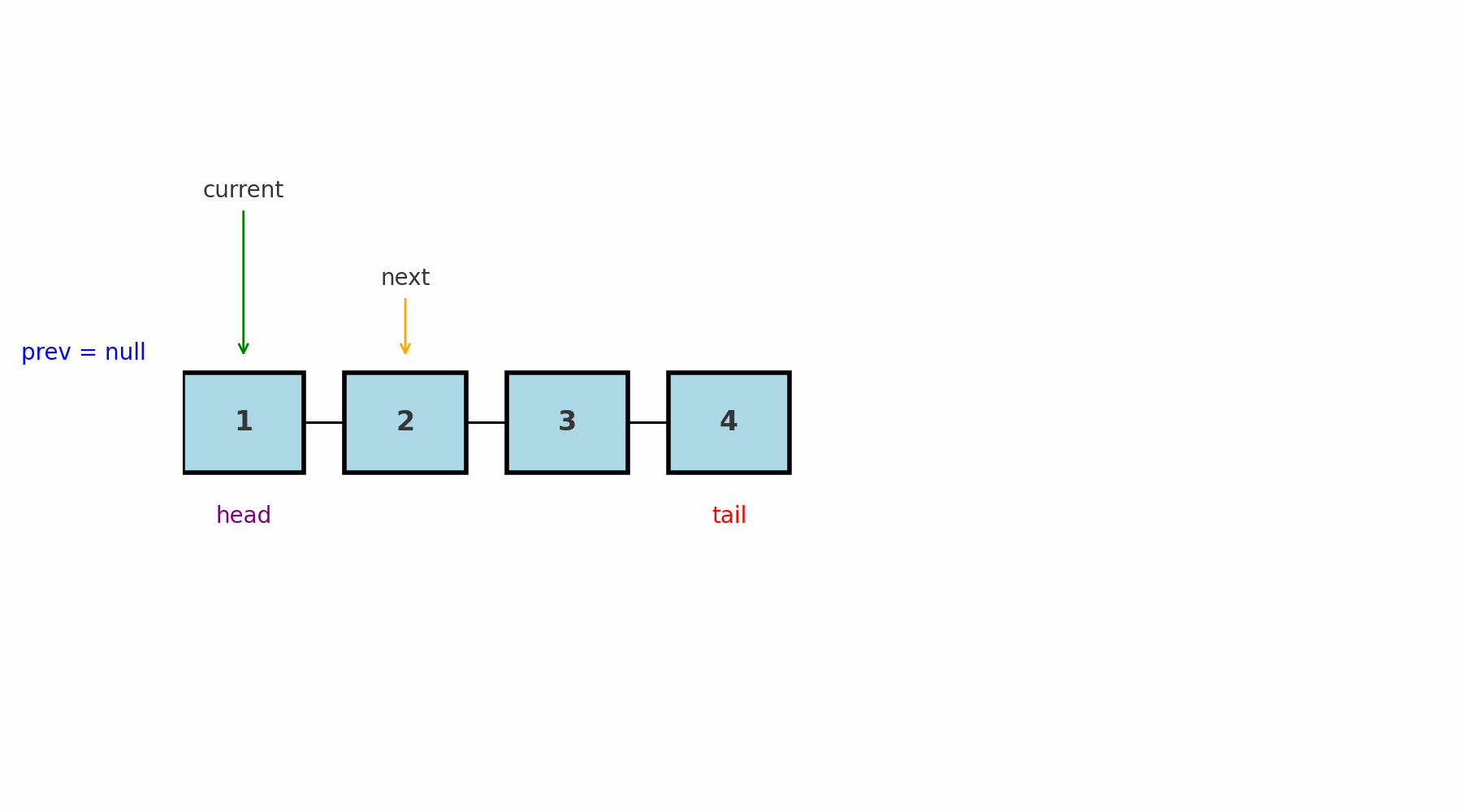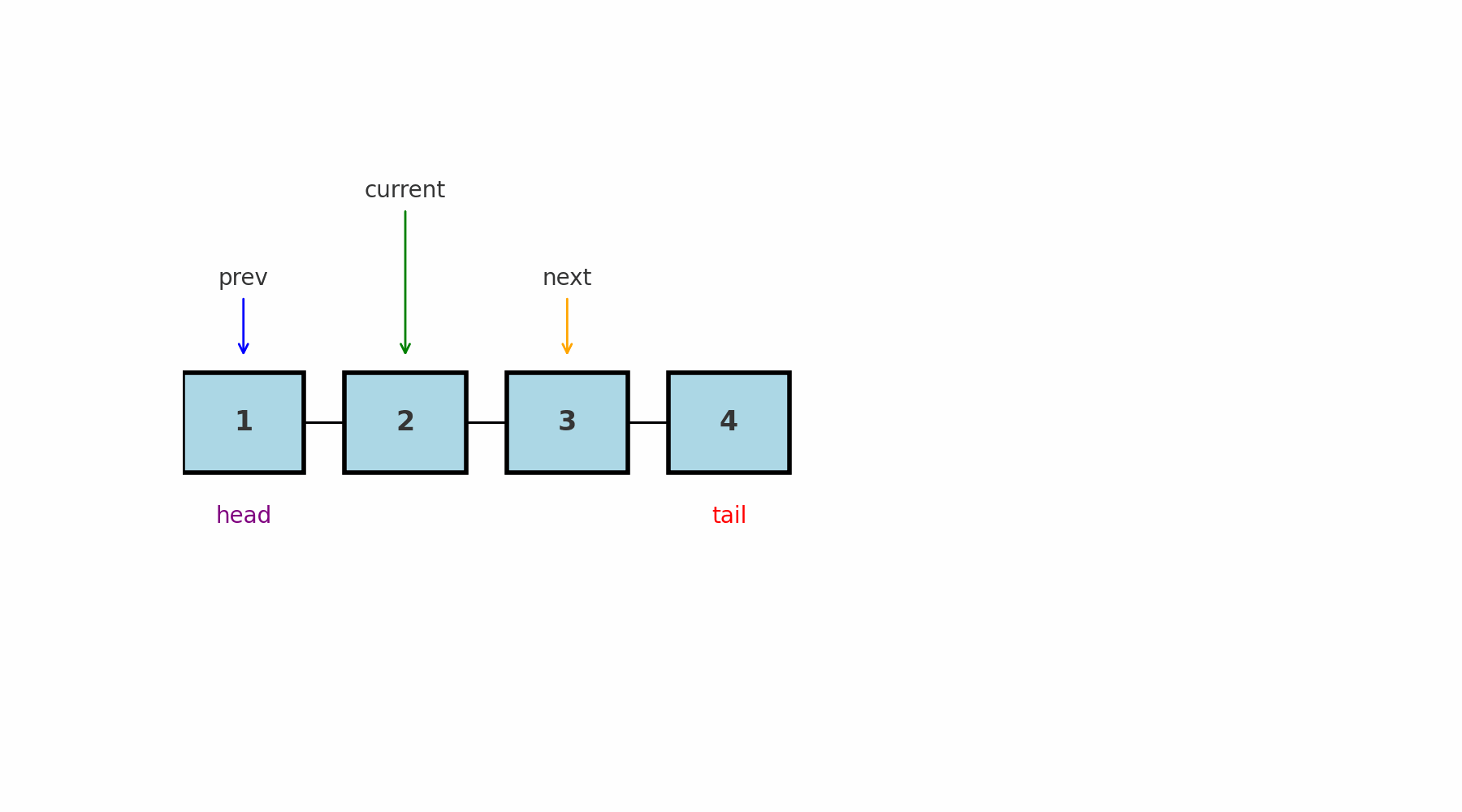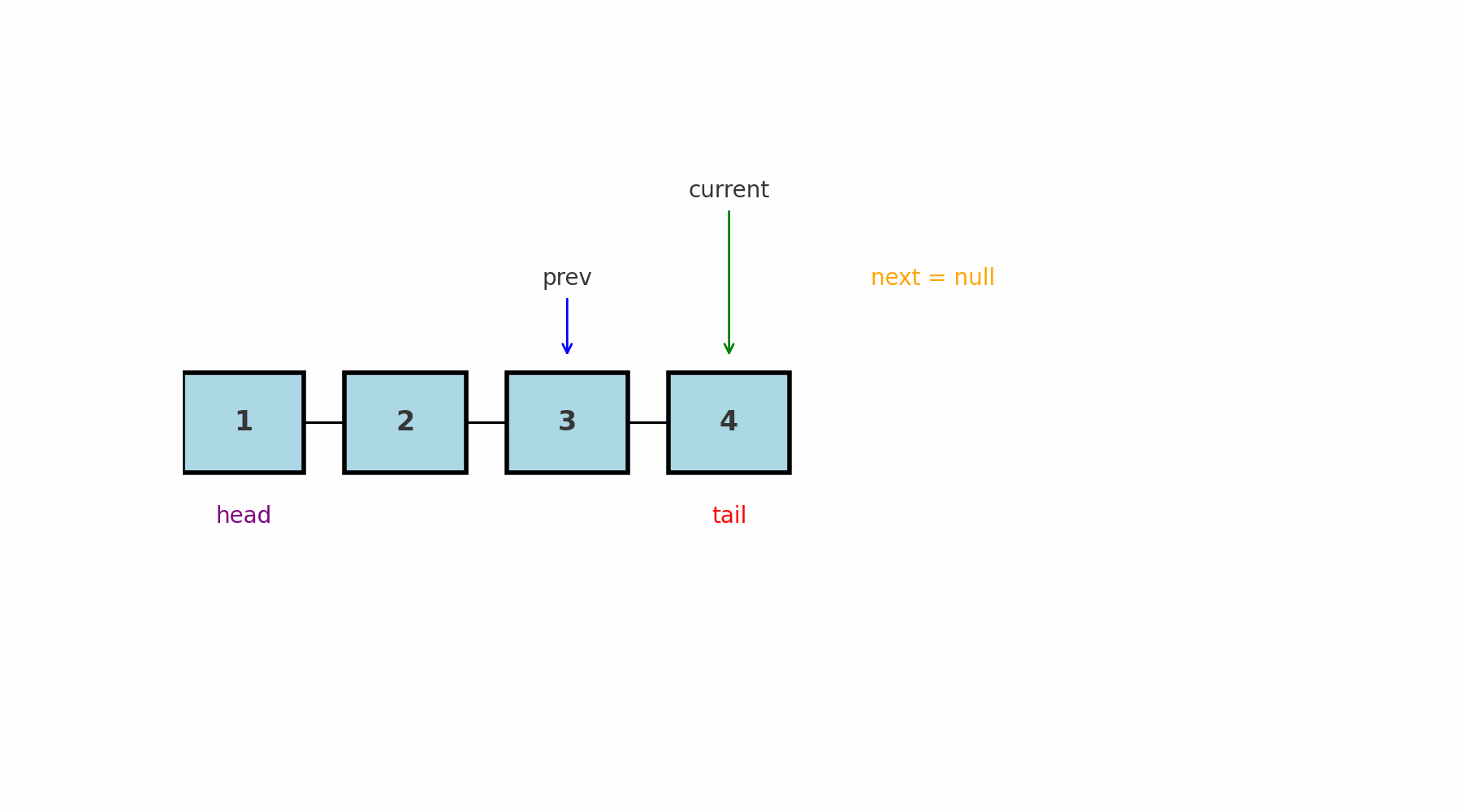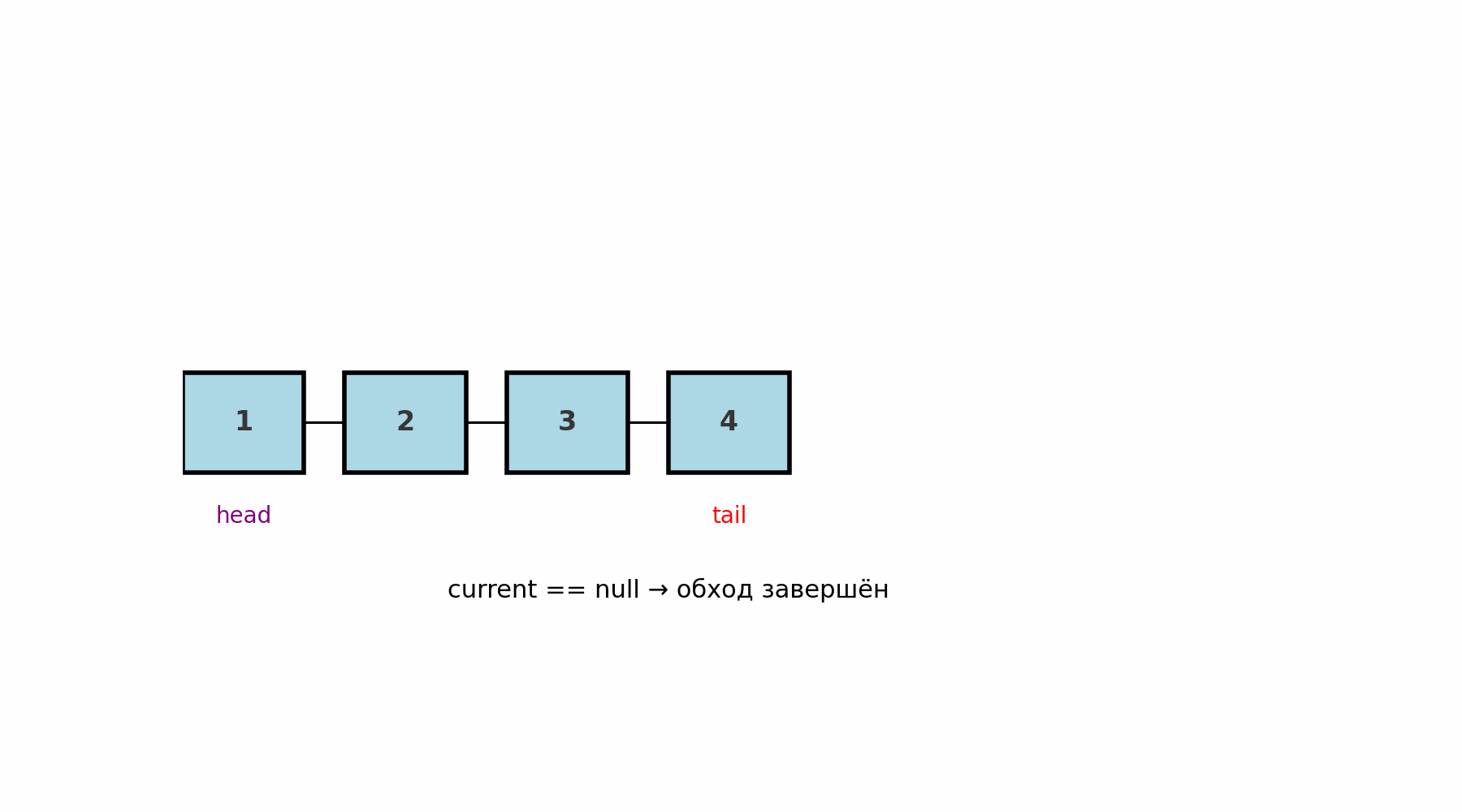
Подводные камни:
После удаления узла нельзя сразу сдвигать
prev, иначе следующий элемент будет пропущен.Если список хранит ссылку на
tail, её нужно обновлять отдельно при изменении последнего элемента.
Ошибки:
Попытка применить технику к двусвязному списку как «обратный обход» — это неверно: для двусвязного списка используется
prevвнутри узлов, а не переменная.Забыта обработка случая
prev == nullпри удалении головы.
Обход до предпоследнего узла (penultimate node)
Идея: пройти список так, чтобы остановиться на узле, который стоит перед хвостом.
Где применяют: удаление последнего элемента, обновление tail в односвязном списке, вставка в конец без сохранённого tail.
Как работает (pseudocode):
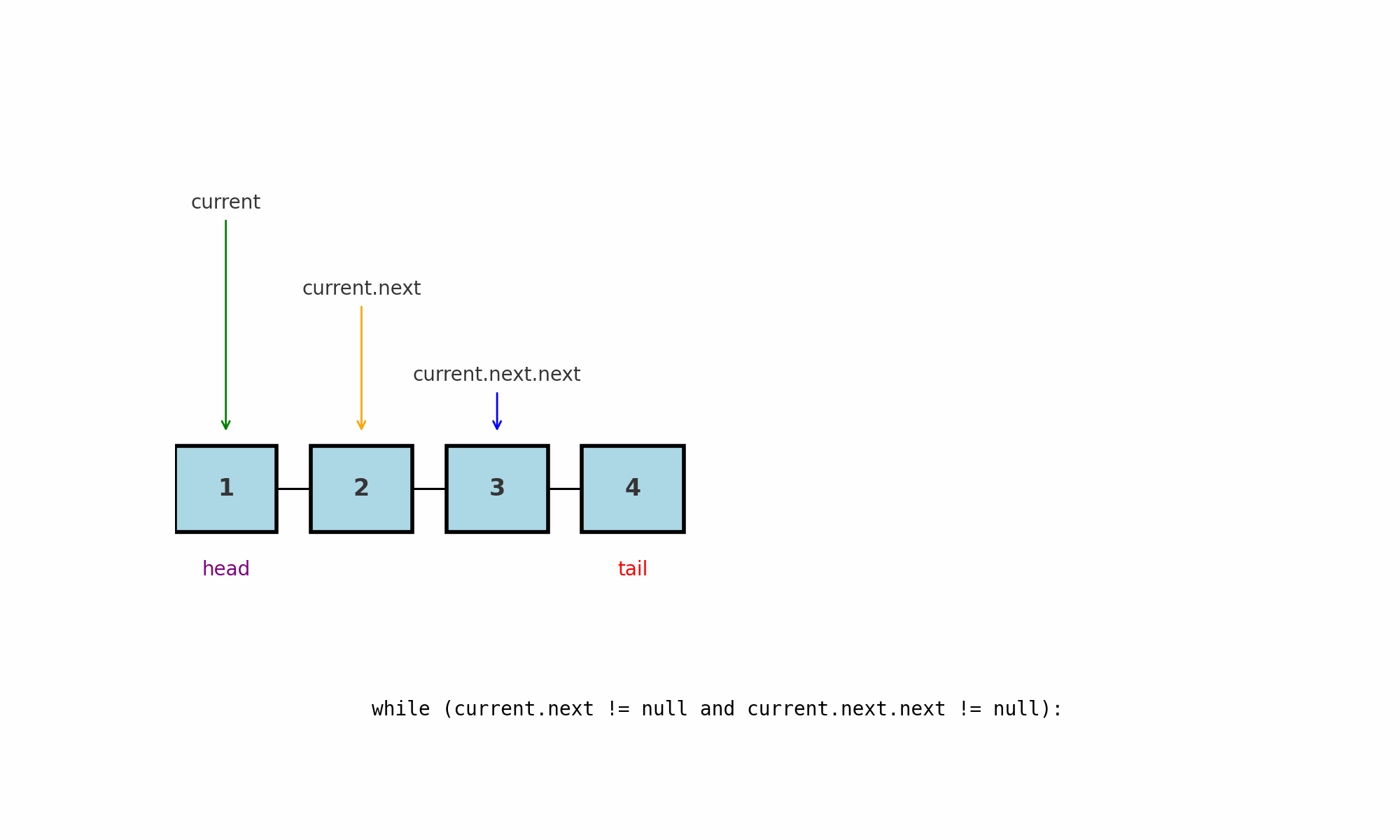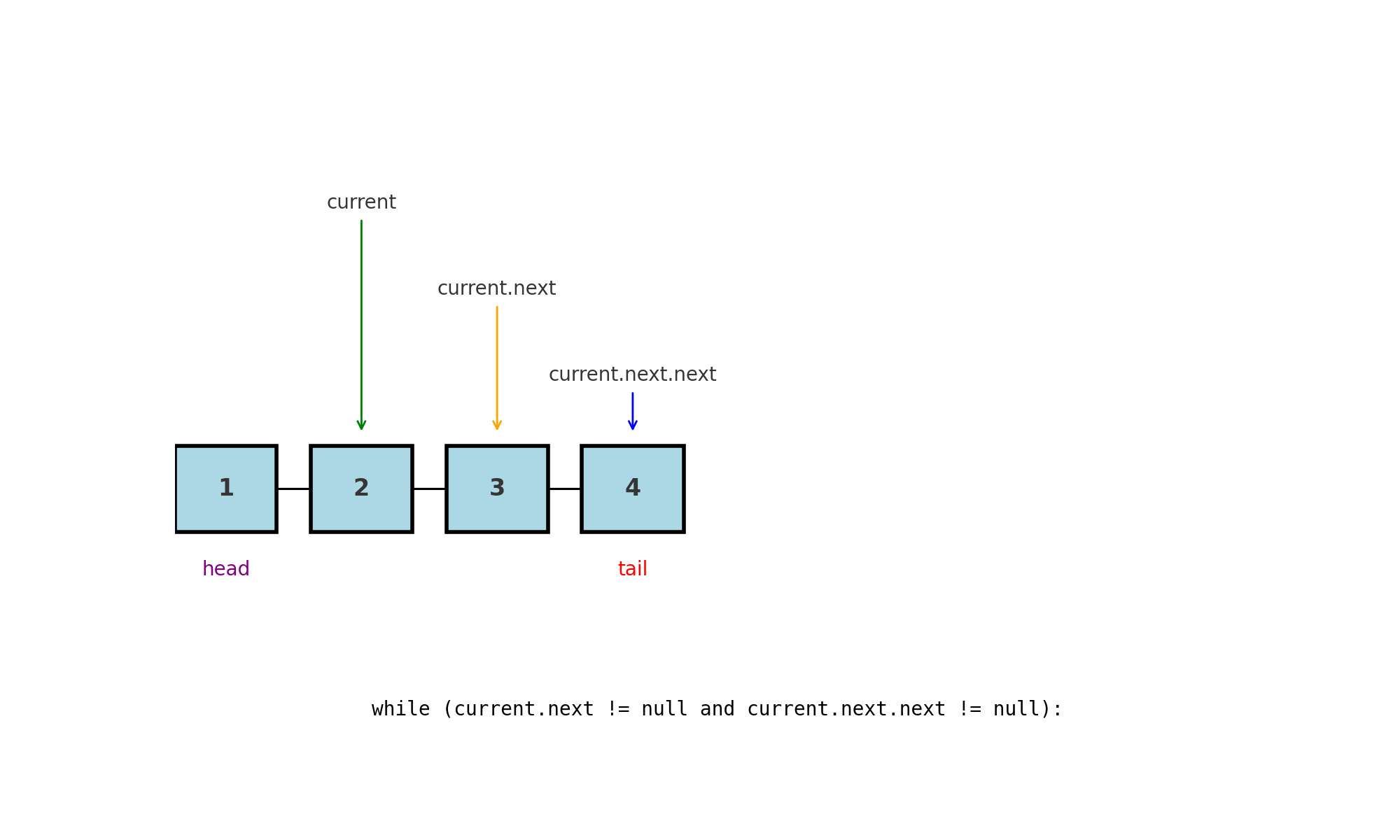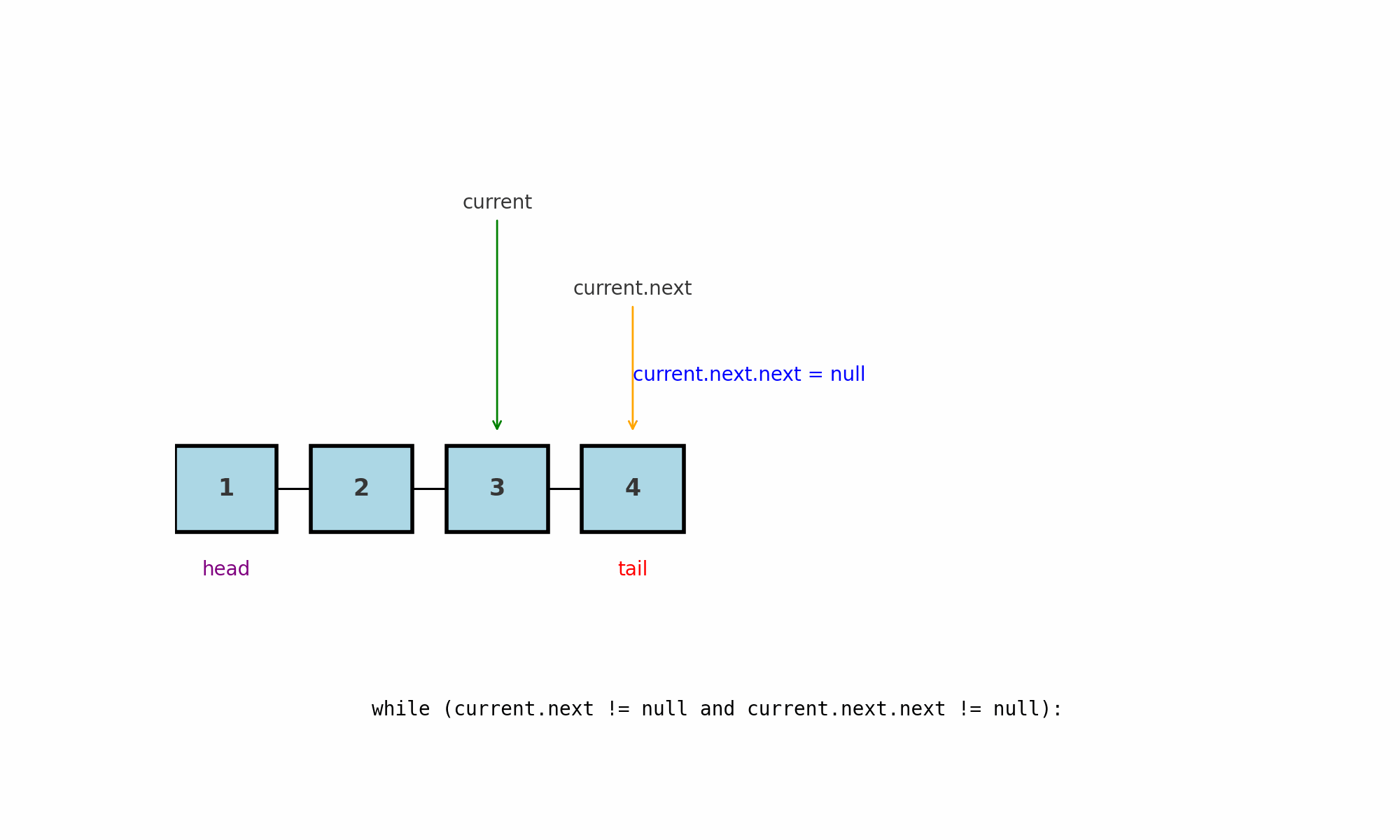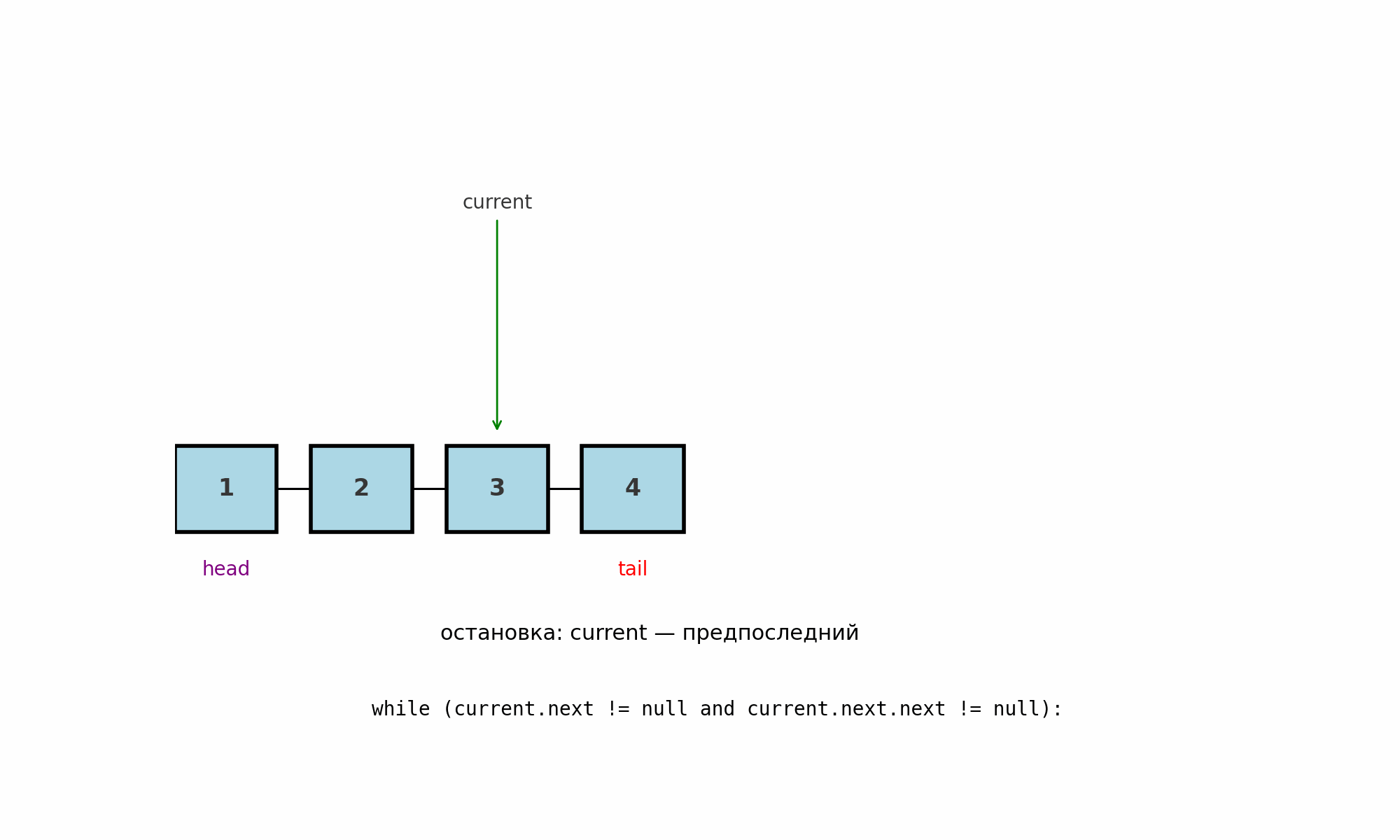
Подводные камни:
Длины 0 и 1: предпоследнего не существует, логику нужно завершать заранее.
Длина 2: цикл не выполнится ни разу, и
currentуже будет указывать на предпоследний.
Ошибки:
Проверка только
current != nullвместоcurrent.nextиcurrent.next.next, что приводит к обращению кnull.После удаления хвоста забыто обнулить
current.next = nullи, при наличии поляtail, не обновлёнtail = current.
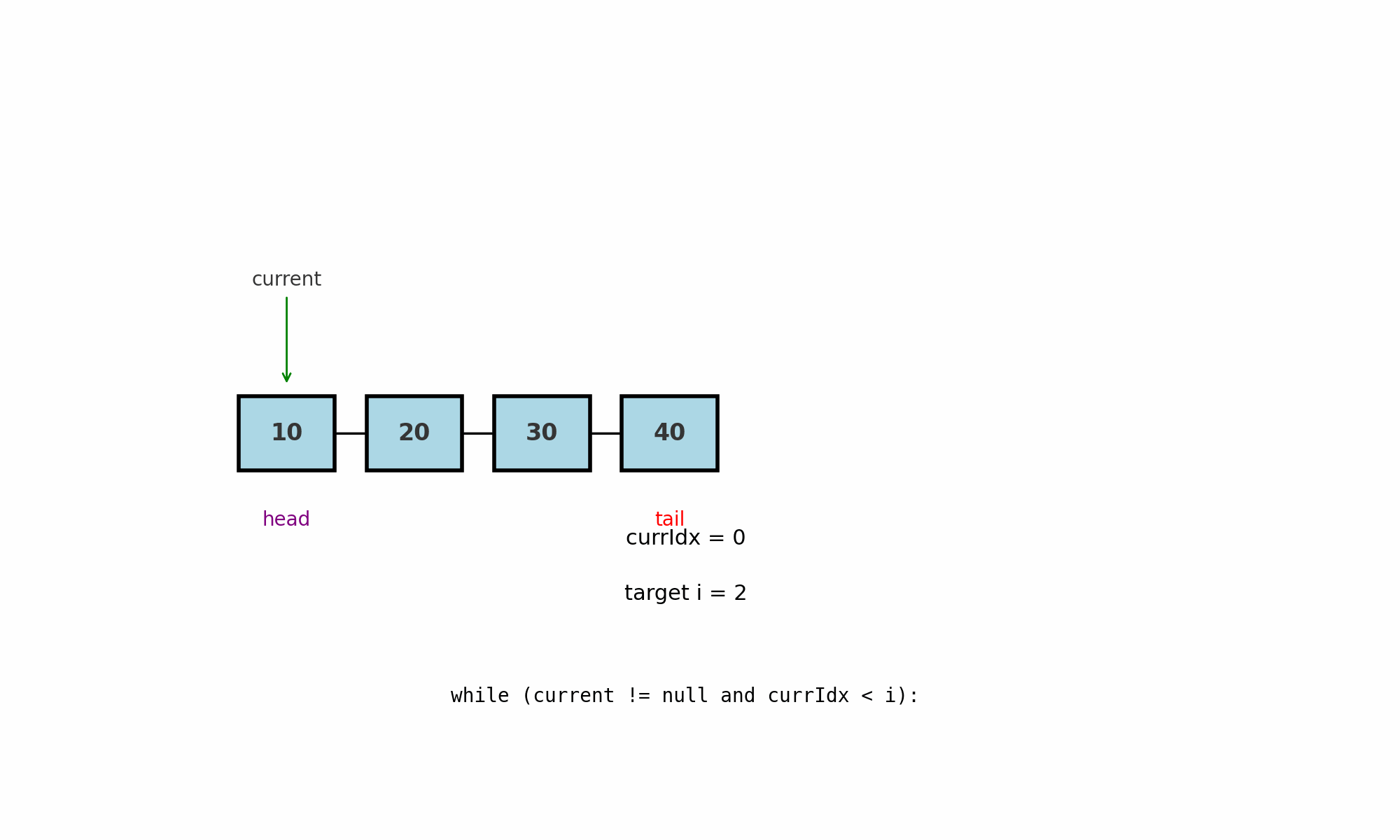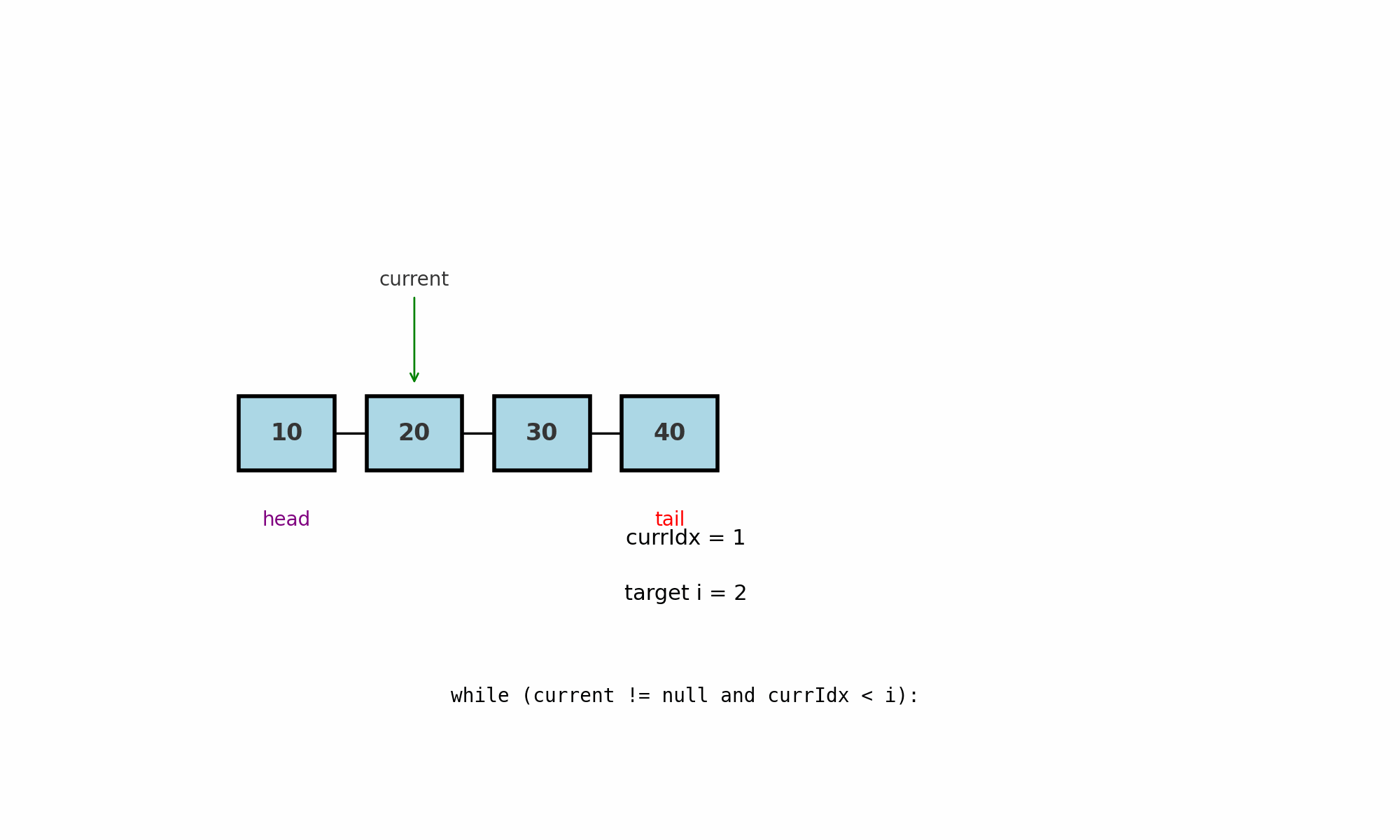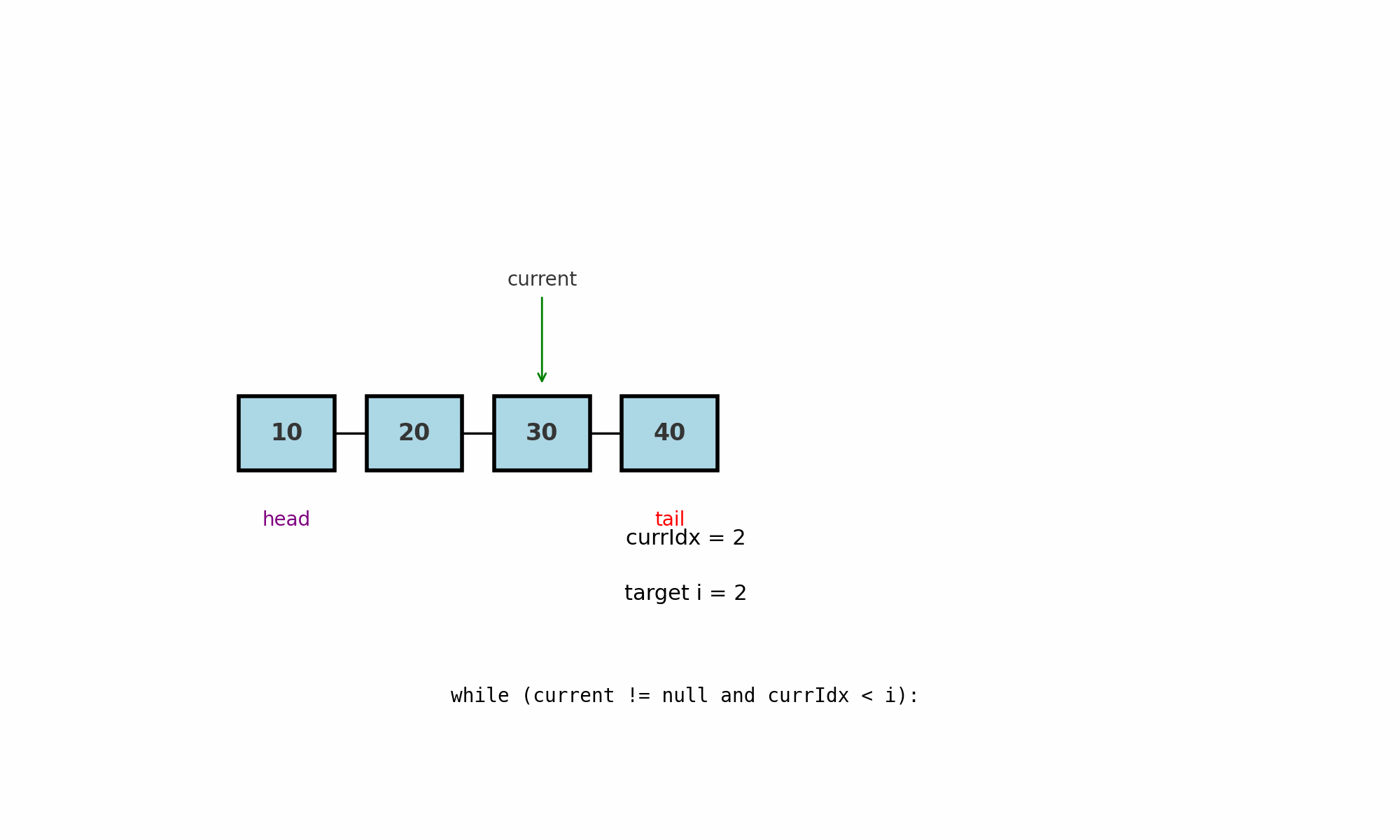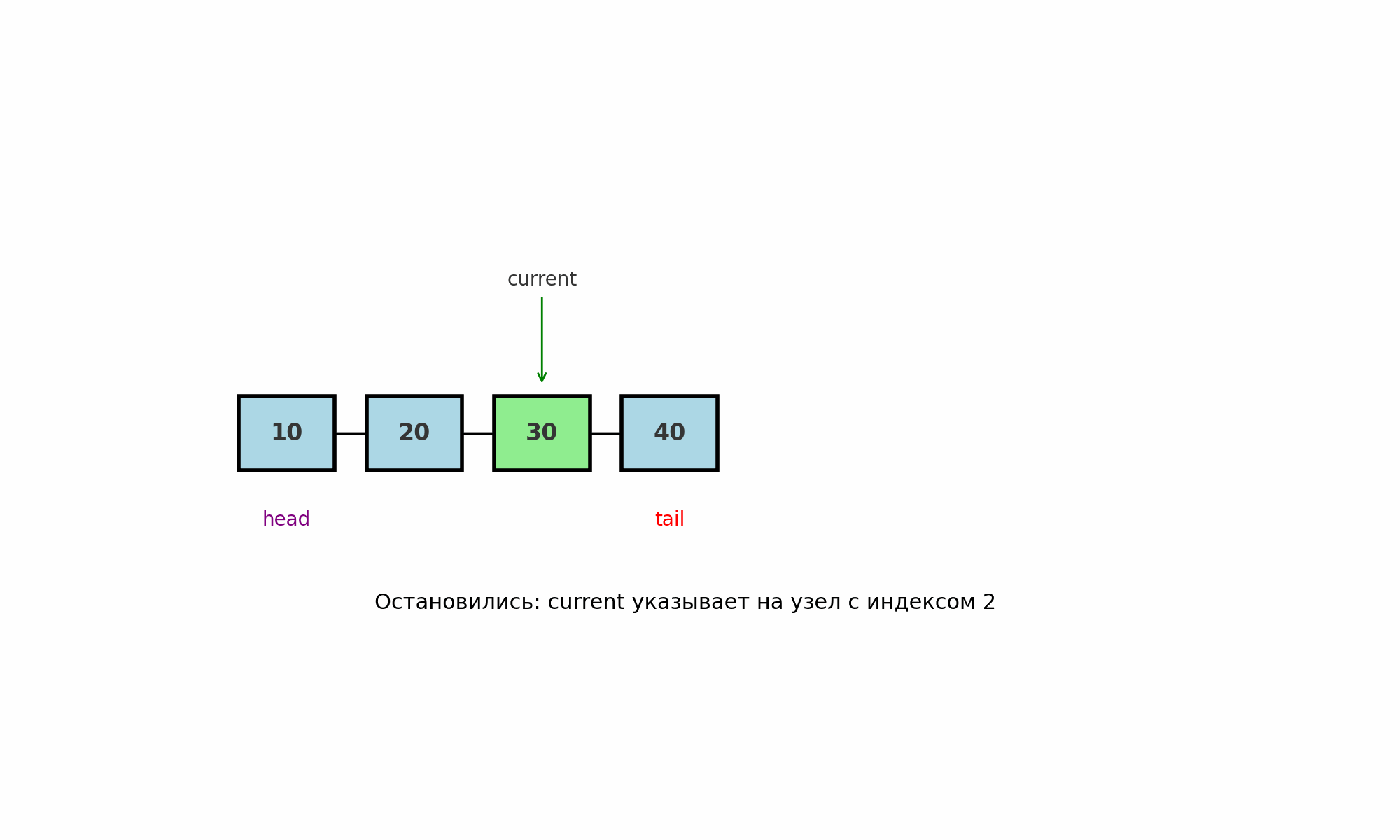
Обход по индексу
Идея: дойти до позиции i последовательным движением от head, так как у LinkedList нету случайного доступа по индексу как в массивах.
Где применяют: вставка или удаление по индексу, доступ к k-му элементу, поиск узла-предшественника для операций в середине.
Как работает (pseudocode):
Подводные камни:
Индекс 0 тут голова (head). Для
i == 0часто лучше вызывать «вставку в голову» или «удаление головы».Если поддерживается
tailи известноsize, тоi == sizeвставка в хвост, удобно делегировать вaddAtTail.Размер может быть неизвестен. Тогда выход за границы нужно обрабатывать по факту
current == null.
Ошибки:
Нет проверки на выход за границы: использование
current.next, когдаcurrent == null.Смешивание логики: попытка вручную обрабатывать все случаи в одном цикле вместо делегирования краевых случаев в Head/Tail.
Неверная остановка цикла (
<=вместо<), что приводит к попаданию на узел с индексомi+1.
Обратный обход (для двусвязного списка)
Идея: идти от хвоста к голове по ссылкам prev. Работает только в двусвязном списке (у каждого узла есть next и prev).
Где применяют: печать в обратном порядке, симметричные проверки (сравнение крайних элементов), задачи «от конца к началу», некоторые реализации LRU.
Как работает (pseudocode):
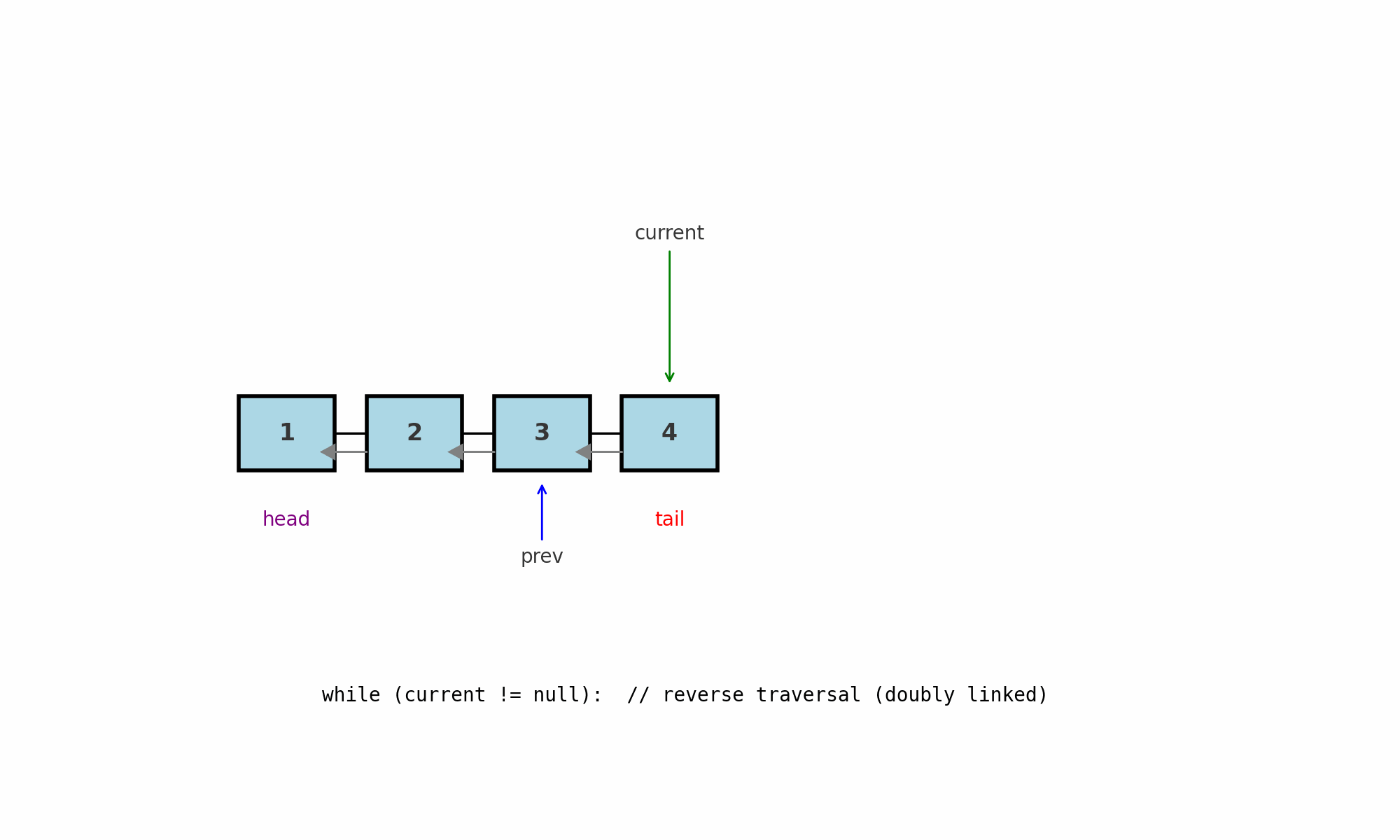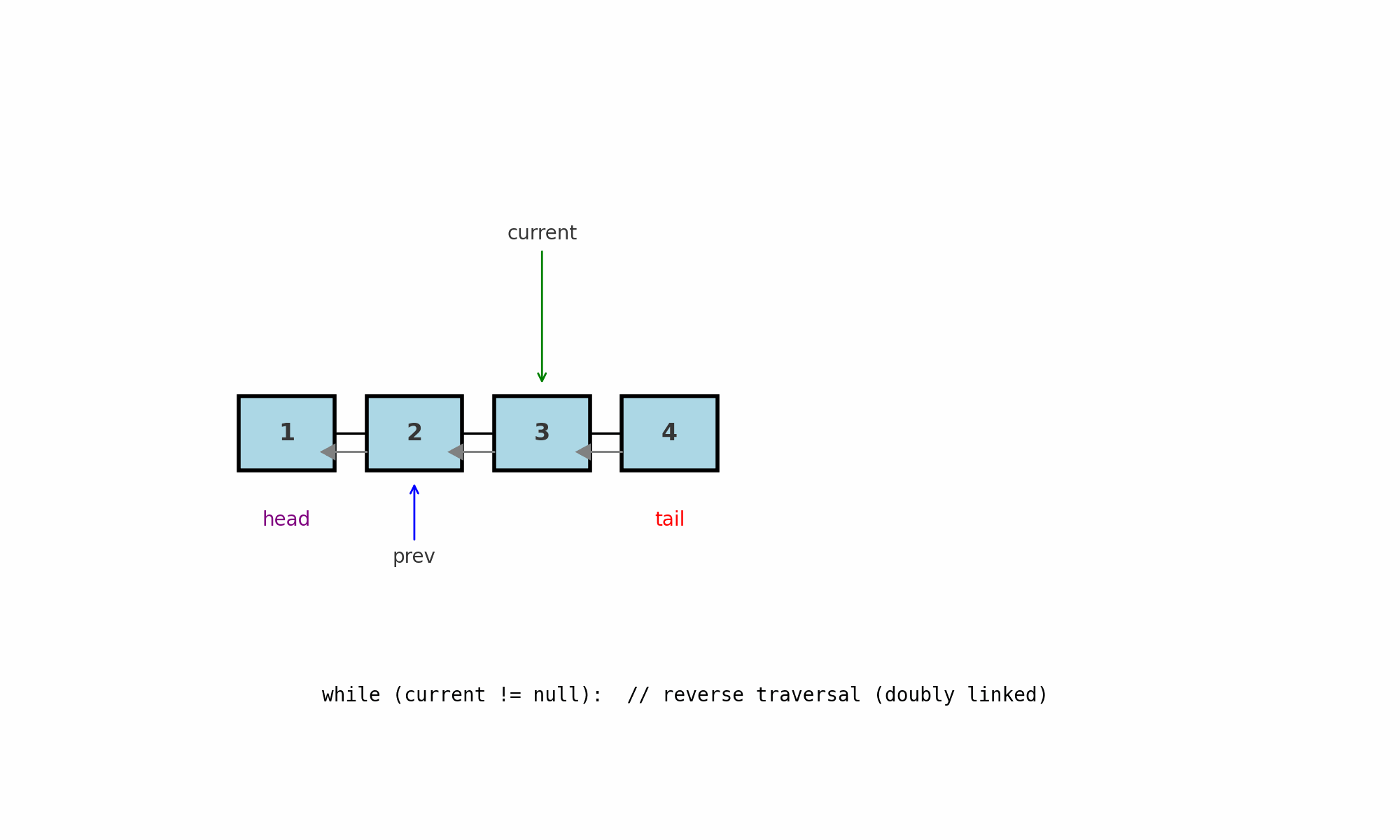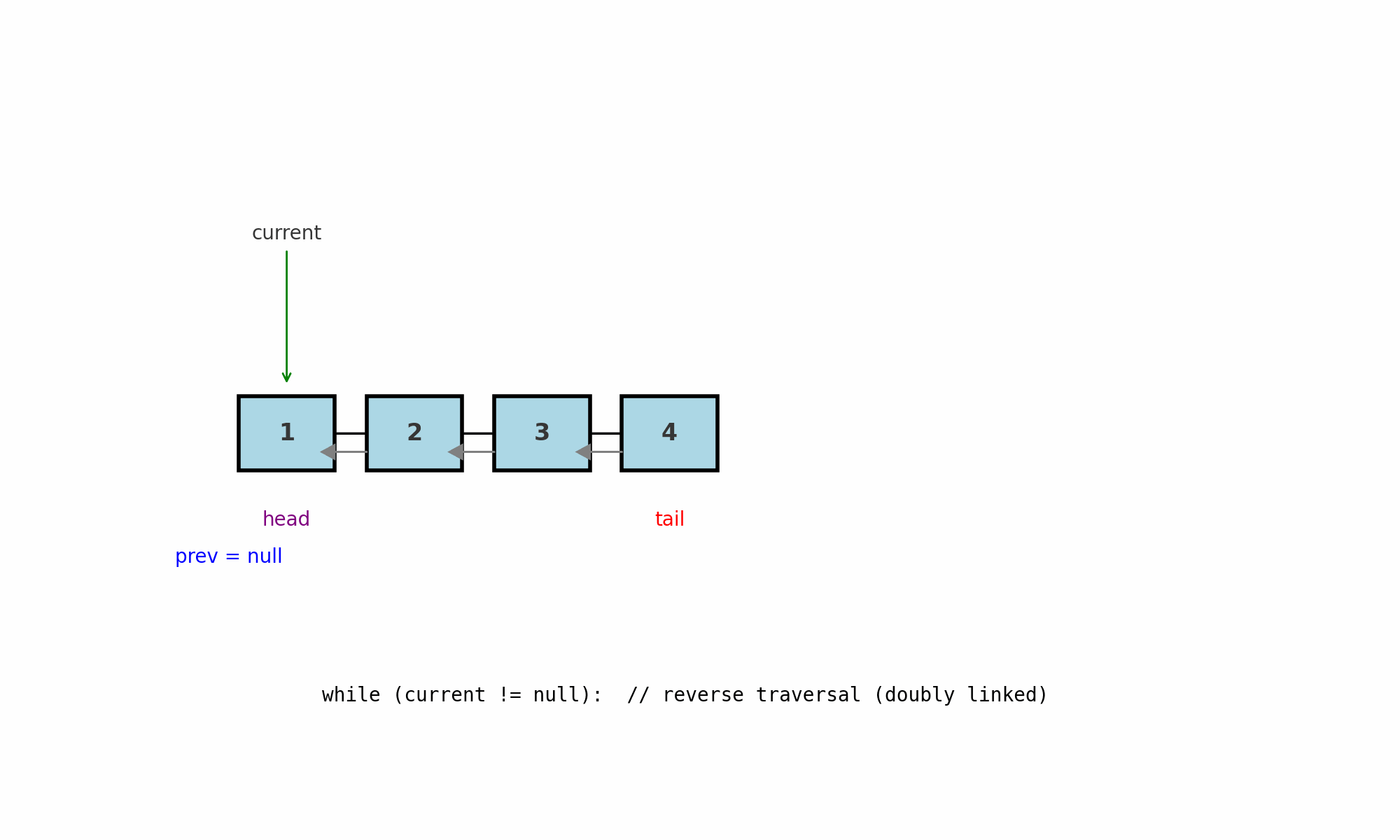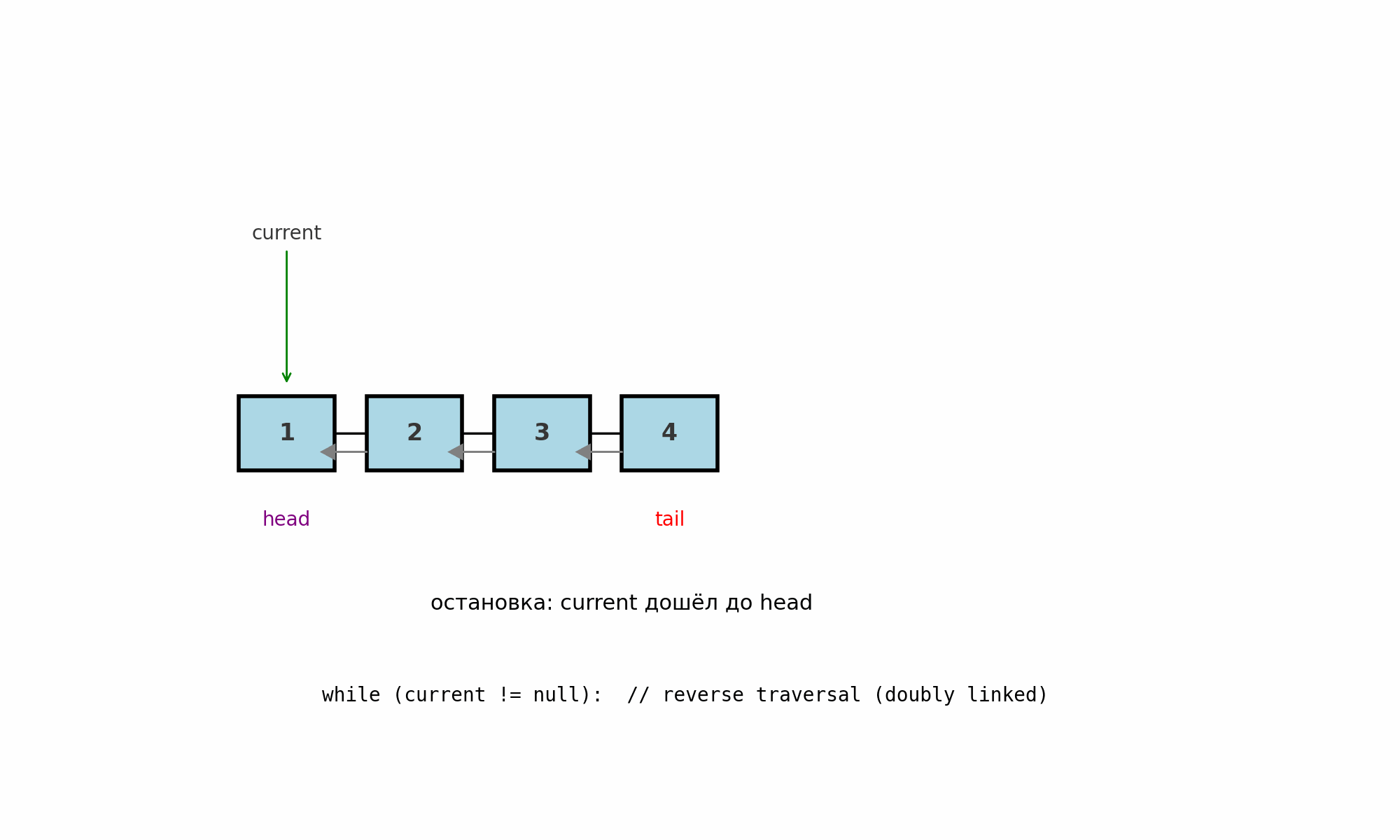
Подводные камни:
При вставках/удалениях нужно обновлять обе ссылки: и
next, иprev; любая несогласованность ломает обход.Если структура хранит
headиtail, убедиться, что они корректно меняются при операциях на краях.
Ошибки:
Попытка сделать обратный обход в односвязном списке (нет
prev).Забыто обновить
prev/nextу обоих соседей при вставке или удалении, из-за чего цепочка рвётся.Неправильная инициализация: начать с
headвместоtail(получится прямой обход).
Пример (Java)
На LeetCode и на собеседованиях обычно дают только
head, чтобы проверить умение работать с указателями. В реальной разработке чаще используют обёрткуLinkedListили готовые коллекции, скрывающие внутреннее устройство.
Recommended LeetCode Practice
Используйте JUMBAQ Framework для систематичного решения leetcode задач
1290. Convert Binary Number in a Linked List to Integer
📌 Главная идея: Traversal это фундаментальная техника для связного списка. Без неё невозможны поиск, удаление, реверс и все более сложные паттерны.
